现在Ai是一个技术热门领域,其中从非结构化数据转换到结构化数据,是时常要面对的问题。我们经常需要从各原始数据中提取文本,这可能是来自docx/ppt/excel/pdf等此类文件。
其中PDF我愿称之为 “文档转换的终点” 因为当你实际操作时,你会发现由其他格式(如docx/html)转换到PDF比较容易,但从PDF转换出来却变得非常困难,特别是那种纯图片形式的、扫描件PDF。“苦PDF久矣~啊”,各位同学。
不要慌,问题与答案往往是相继出现的,只要我们不停下探索的脚步。在本文中 我通过实际测验市面上评分较高的一些工具、项目,基本上包含了你在网上能找到的最优的技术方案,大部是开源的,也有个别是非开源的。 下面将向大家逐一介绍。
在下面的项目中我们使用下面的2份纯图片形式的求职简历作为输入,来测试OCR模型的识别和提取能力。
原内容


MinerU
MinerU是由上海人工智能实验室OpenDataLab团队开发的开源智能数据提取工具,专注于高效解析复杂文档(如PDF、网页、电子书),并将其转换为结构化的机器可读格式(如Markdown、JSON)。该项目凭借其强大的多模态解析能力,能够精准识别文本、表格、图片、数学公式(支持LaTeX转换)及复杂排版,并自动去除页眉、页脚、页码等冗余信息,保留原始文档的语义逻辑与结构。MinerU支持176种语言识别,兼容CPU/GPU/NPU加速,适用于学术研究、企业数据处理、大模型训练等场景
开源许可AGPL-3.0
- • 源代码公开:如果一个程序以AGPL-3.0授权,并且你通过网络为他人提供了该程序的服务(比如SaaS),那么即使你没有直接分发该程序的副本,你也必须向用户提供源代码,包括任何修改过的版本。
- • 衍生作品:使用了AGPL-3.0许可代码的衍生作品也必须采用相同的许可证进行发布。
- • 兼容性:AGPL-3.0与GPL-3.0保持一致,允许各自的组件保持其原有的授权,但当涉及到网络服务时,GPL授权的组件也需要遵守AGPL的要求,即提供源代码
若企业使用AGPL-3.0软件提供网络服务(如SaaS),必须向用户公开完整源代码及修改内容;其强传染性要求衍生作品也需开源,可能迫使整个商业项目开放源码。如果仅在企业内部使用(非对外服务),则无需公开源代码。若企业希望避免开源代码,可与原作者协商 闭源授权(需支付费用)。
转换效果
MinerU的识别效果,总体上来算可以,核心内容是没有太大问题,不足的地方是还是有一些排版错乱的问题,如下图中:“技能评价”被横插到了“实践经历”的内容中,而且有些内容的字号设置不是太准确,三级标题和二级标题一样大。
 MinerU识别效果
MinerU识别效果在线体验
- • MinerU官网:https://mineru.net/OpenSourceTools/Extractor?source=github
- • ModelScope:https://www.modelscope.cn/studios/OpenDataLab/MinerU
- • HuggingFace:https://huggingface.co/spaces/opendatalab/MinerU
- • Github仓库:https://github.com/opendatalab/MinerU
mPLUG-DocOwl 1.5
阿里巴巴mPLUG团队在多模态文档图片理解领域的最新开源工作,在10个文档理解benchmark上达到最优效果,5个数据集上提升超过10个点,部分数据集上超过智谱17.3B的CogAgent,在DocVQA上达到82.2的效果
开源许可Apacha-2.0
Apache License 2.0协议允许用户自由使用、修改和分发软件,同时提供专利授权保护,并且不要求公开衍生作品的源代码。使用该许可证的项目时,需要注意保留版权声明和许可证副本,清晰标注所做的任何修改,注意潜在的专利诉讼风险,以及遵守商标使用的相关规定,以确保法律合规性和促进开源社区健康发展。
以下是该许可证的一些关键特性:
• 专利授权:如果软件的原始贡献者拥有相关的专利权,则这些专利会在许可证下自动授予用户,但仅限于使用这些专利的权利,而不包括制造或销售产品。
• 分发代码:你可以在任何项目中使用遵循Apache 2.0许可的代码,无论是开源还是闭源项目,并且无需公开你的修改内容。
• 商标使用:该许可证不授予使用贡献者的名字、标志或其他商标的权利。
• 免责声明:该许可证包含一个明确的免责声明,表明软件“按原样”提供,没有任何形式的保证。
Apache 2.0 是商业友好的开源协议,允许灵活使用代码但需严格保留声明。商用时需重点关注版权声明、专利授权和免责声明,避免因忽略条款导致法律风险。
转换效果
mPLUG-DocOwl 1.5的识别效果,内容丢失比较严重,在排版中也存在一些问题,例如标题重复,内容重复等问题。算识别效果比较差的一个。
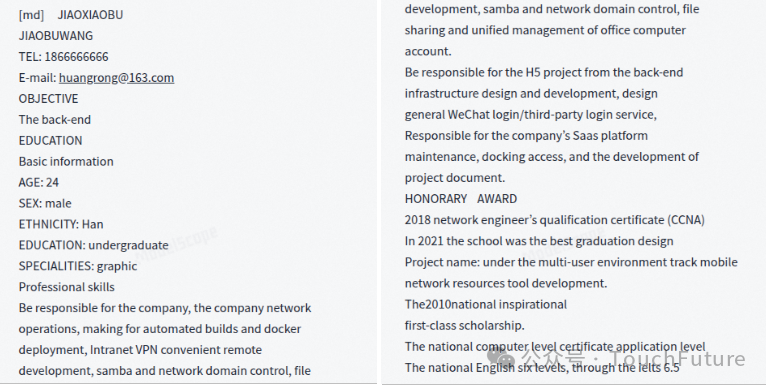 mPLUG-DocOwl 1.5识别效果
mPLUG-DocOwl 1.5识别效果在线体验
- • ModelScope:https://modelscope.cn/studios/iic/mPLUG-DocOwl/
- • HuggingFace:https://huggingface.co/spaces/mPLUG/DocOwl
- • GitHub仓库:https://github.com/X-PLUG/mPLUG-DocOwl
Mistral OCR
Mistral OCR是由法国Mistral AI开发的高性能光学字符识别工具,专为处理复杂文档设计,具备高精度解析(支持文本、图像、表格、数学公式等)、多语言识别(覆盖千种语言,准确率达99.02%)、极速处理能力(单节点每分钟2000页)及结构化输出(JSON/Markdown/HTML格式保留原始排版)等核心优势。
目前提供API版本(mistral-ocr-latest),通过开发者平台La Plateforme提供,定价为每1000页1美元。
转换效果
经过实测,Mistral OCR转换效果确实惊艳,几乎没有丢失任何信息内容,没有排版错乱问题,生成的Markdown内容干净整洁。唯一不足的是没有设置标题,所有内容都是同一字号。
 Mistral OCR转换效果
Mistral OCR转换效果在线体验
- • 官方网站:https://mistral.ai/news/mistral-ocr
- • 在线体验地址:https://mistralocr.org/zh-CN/
Got OCR 2.0
GOT-OCR 2.0 是一个基于通用 OCR 理论(General OCR Theory)的统一端到端模型,由 StepFun、旷视科技、中国科学院大学和清华大学联合开发,旨在推动 OCR 技术进入 OCR-2.0 时代。该模型具备处理多种类型内容的能力,包括普通文本、数学公式、分子结构、表格、图表、乐谱等,并通过端到端架构、Flash-Attention 技术优化以及动态分辨率处理,实现了高效识别与格式化输出(如 Markdown/LaTeX)。
转换效果
Got OCR 2.0识别出了大部分内容,有轻微丢失,没有排版整个结果内容全在一行中,有轻微的内容错乱。
 Got OCR 2.0识别结果
Got OCR 2.0识别结果在线体验
- • ModelScope:https://www.modelscope.cn/studios/stepfun-ai/GOT_official_online_demo
- • Github仓库:https://github.com/Ucas-HaoranWei/GOT-OCR2.0
Dolphin
Dolphin是字节跳动开源一款文档解析模型。与目前市面上各类大模型相比,这款轻量级模型不仅体积小、速度快,并且取得了令人惊艳的性能突破,解析效率提升近2倍。
开源许可MIT
MIT许可证是一种宽松的开源软件许可协议,最初由麻省理工学院(Massachusetts Institute of Technology, MIT)制定。它给予软件用户很大的自由,仅要求保留版权声明和许可声明即可。
在商业使用MIT许可软件时,需注意保留原始版权声明和许可协议、接受“无担保”条款、避免法律责任、确保合规使用及分发、不得擅自使用原作者品牌或商标,并留意与其他软件的兼容性。
转换效果
在实际体验上Dolphin转换速度比较快,但是和MinerU一样的问题,部分排版错乱、有部分信息(电话号码)丢失问题。
 Dolphin识别效果
Dolphin识别效果在线体验
- • 在线Demo:http://115.190.42.15:8888/dolphin/
- • Github仓库:https://github.com/bytedance/dolphin
Monkey OCR
MonkeyOCR 是华中科技大学与金山办公联合开发的高效文档解析模型,基于创新的SRR(Structure-Recognition-Relation)范式,精准提取PDF/图片中的文本、公式(LaTeX)、表格(JSON)等内容并结构化输出,支持Markdown/JSON格式导出。其30亿参数模型在英文文档解析中超越Gemini 2.5 Pro等大模型,处理速度达0.84页/秒,且可在单块3090 GPU上运行。
开源许可Apache2.0
关于Apache2.0许可和商用注意事项参考上文。
转换效果
Monkey OCR的信息保留度很高,虽然有些是以图片形式保存了下来,但是文字是文字、图片仅仅是图片而已。而在布局上没有发生混乱,原先简历中的双栏内容,被按由左至右由上至下的顺序正确的识别了,唯一问题是标题级别设置上有偏差。
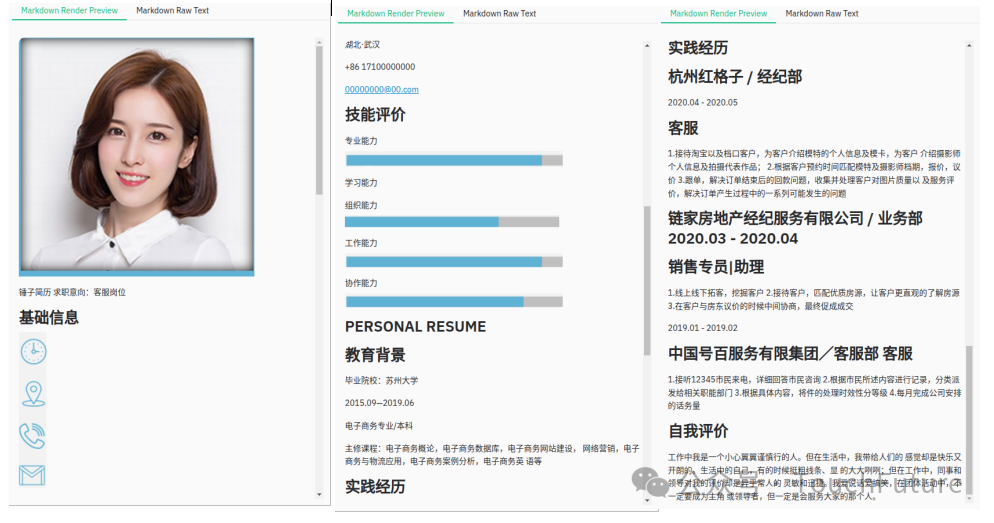 MonkeyOCR识别效果
MonkeyOCR识别效果Nanonets-OCR-S
Nanonets-OCR-s 是由 Nanonets 于 2025 年 6 月 10 日发布的光学字符识别(OCR)模型。该模型基于Qwen2.5-VL-3B微调,运行至少需要9G显存。
开源许可Apache2.0
关于Apache2.0许可和商用注意事项参考上文。
转换效果
Nanonets-OCR-S的转换效果,说实话惊㤉到我了,几乎趋于完美,我个人认为文档写到这里为止,是体验过转换效果最好的一个。内容识别完整,虽然不像Monkey OCR带图片,其实应该也可以(自己改造一下)布局准确,尽然还使用的表格来组织简历中的基础信息。更关键的是标题设置完全没毛病,非常准确。
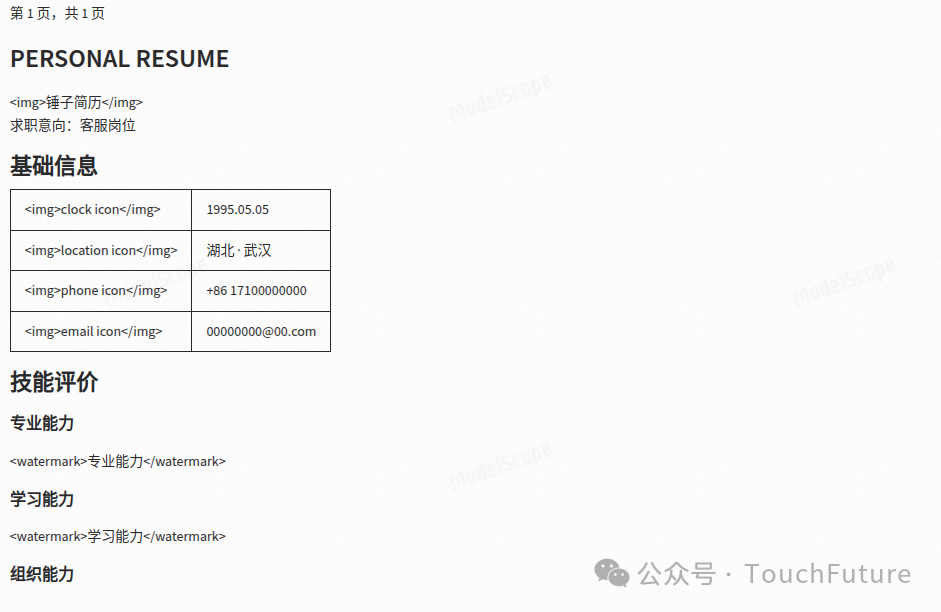 Nanonets-OCR-S识别效果01
Nanonets-OCR-S识别效果01 Nanonets-OCR-S识别效果02
Nanonets-OCR-S识别效果02 Nanonets-OCR-S识别效果03
Nanonets-OCR-S识别效果03在线体验
- • ModelScope:https://www.modelscope.cn/studios/nanonets/Nanonets-ocr-s/summary
- • Github仓库:https://github.com/NanoNets/docext
OCR Flux
OCRFlux 是一款基于 多模态大语言模型(VLM) 的工具包,专为将 PDF 文档和图像转换为结构清晰、可读性强的 Markdown 文本 而设计。一张12GB GPU 内存的RTX-3090显卡可以部署运行。
开源许可Apache2.0
关于Apache2.0许可和商用注意事项参考上文。
转换效果
OCR Flux识别结果,文字保留相对完整,标题设置没有太大问题,唯一的不足之处是在简历中的“技能评价”处,标题设置不准确,有些是内容的部分被标记为标题,导致字体太大了。如果没有这一点问题的话,感觉和Nanonets-OCR-S不分上下。
 OCR Flux识别效果
OCR Flux识别效果在线体验
- • 官方Demo:https://ocrflux.pdfparser.io
- • Github仓库:https://github.com/chatdoc-com/OCRFlux
OLM OCR
olmOCR 是由 Allen Institute for Artificial Intelligence (AI2) 的 AllenNLP 团队开发的一款开源工具,旨在将PDF文件和其他文档高效地转换为纯文本,同时保留自然的阅读顺序。它支持表格、公式、手写内容等。
开源许可Apache2.0
关于Apache2.0许可和商用注意事项参考上文。
转换效果
olm OCR的转换效果还是不错的,在结果中去掉了图片部分,内容结构有序,信息完整。没有设置标题部分,字体是统一大小,内容排版无错乱。整体来说,这个效果要比Mistral OCR要稍好一些。
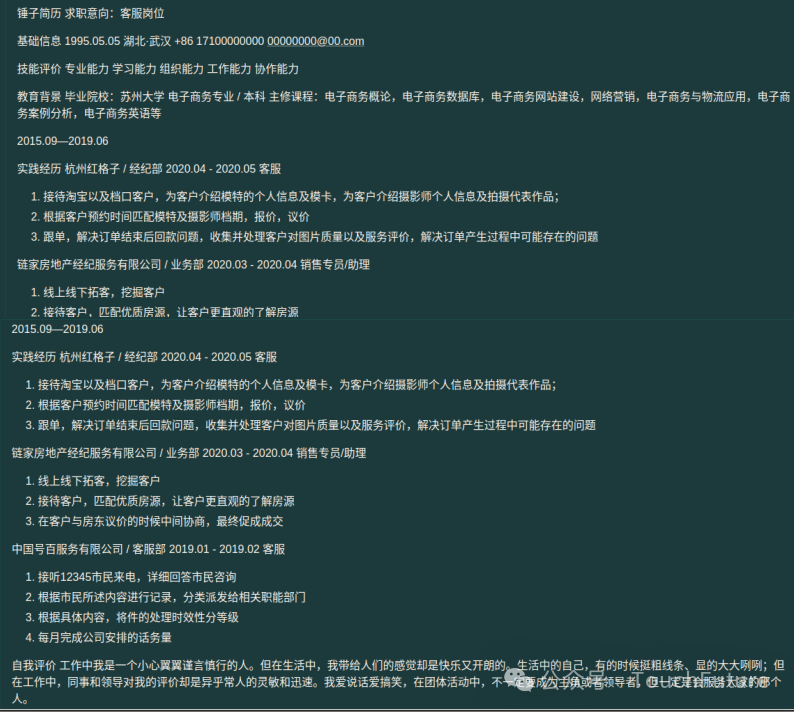 olmOCR识别效果
olmOCR识别效果在线体验
- • 官方Demo:https://olmocr.allenai.org
- • Github仓库:https://github.com/allenai/olmocr
Smol Docling
SmolDocling(SmolDocling-256M-preview )是高效轻量级的多模态文档处理模型。能将文档图像端到端地转换为结构化文本,支持文本、公式、图表等多种元素识别,适用于学术论文、技术报告等多类型文档。模型参数量256M。使其能够在消费级显卡(如 RTX 3060 等)上流畅运行。
开源许可MIT
关于MIT许可和商用注意事项参考上文。
转换效果
Smol Docling的转换效果,整体上还算可以内容结构上没有混乱,但是在第二段工作经历中丢失了日期信息。
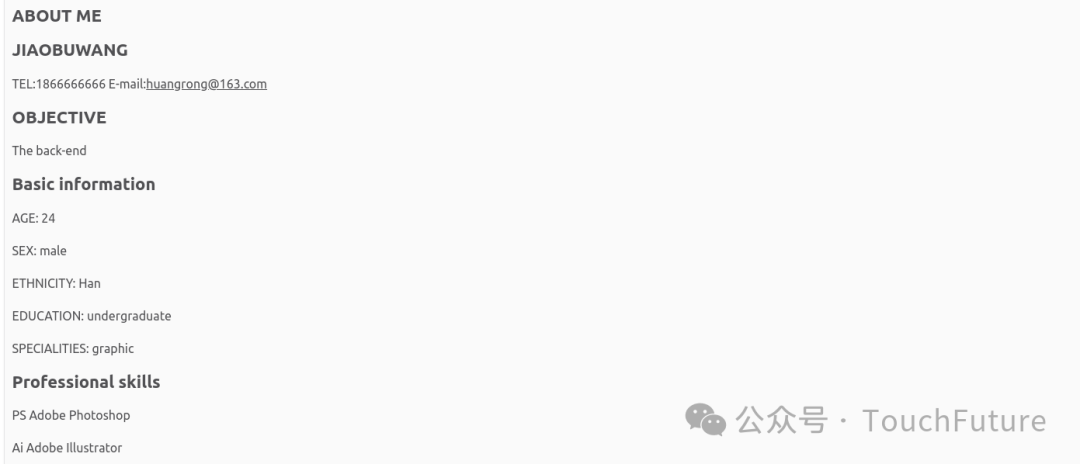 Smol Docling识别结果1
Smol Docling识别结果1 Smol Docling识别结果2Smol Docling识别结果3
Smol Docling识别结果2Smol Docling识别结果3在线体验
- • huggingface:https://huggingface.co/spaces/ds4sd/SmolDocling-256M-Demo
- • Github仓库:https://github.com/AIAnytime/SmolDocling-OCR-App
总结
经过实际测试了这么多款的OCR项目,如果从本次测试结果来看,我个比较倾向于Nanonets-OCR-S、olm OCR和OCR Flux这三款,感觉它们在识别结果上很不错,而且差距不是太大,特别是Nanonets-OCR-S。
当然也可能是我实际测试的数据样本的问题。使用更多的样本去测试也可能会得到不一样结果。去评价哪个工具的好坏也不是本文的目的。希望感兴趣的同学能够通过本文了解到这些工具、开源项目,你们可以实际的去测测、用一用,选择一个适合自己实际需求的,能给大家提供一个解决问题的方案和思路。






 400 186 1886
400 186 1886


