
在软件开发领域中,数据结构是我们能够有效地组织、存储和操作数据的基本构建块。无论你是初学者还是经验丰富的开发人员,掌握常见的数据结构对于编写高效且优化代码都至关重要。
在今天的文章中,我们将探讨每个程序员都应该熟悉的8种基本数据结构,并提供清晰的解释和相关示例,以帮助你了解它们的重要性和应用。
1. 数组:多功能主力
什么是数组?
数组可能是编程中最基本、使用最广泛的数据结构。将数组视为存储在连续内存位置的项目集合。它就像学校里一排储物柜,每个储物柜(元素)按顺序编号,可容纳一个物品。
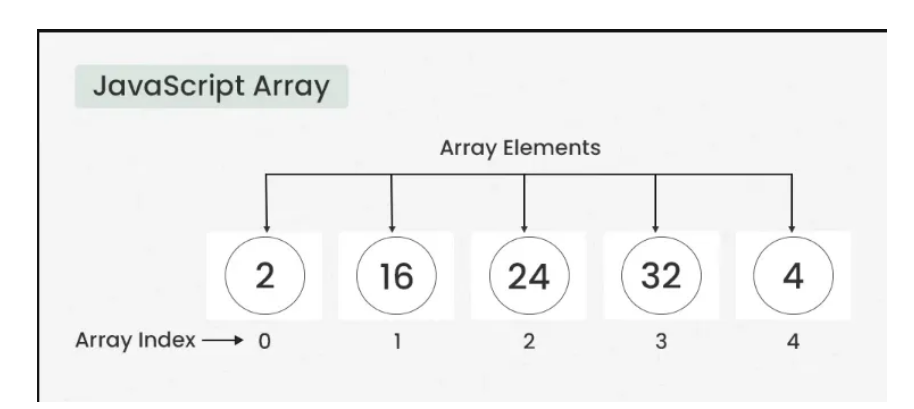
数组如何工作?
数组基于索引的访问原理工作。数组中的每个元素都与一个索引相关联,通常从 0 开始。这样可以快速直接地访问数组中的任何元素。
示例:书架类比
假设你有一个书架,上面有 5 个插槽,编号为 0 到 4。每个插槽可以容纳一本书。这类似于大小为 5 的数组。
# Creating an array (bookshelf) in Pythonbookshelf = ["Harry Potter", "Lord of the Rings", "Pride and Prejudice", "1984", "To Kill a Mockingbird"]
# Accessing elementsprint(bookshelf[0]) # Output: Harry Potterprint(bookshelf[2]) # Output: Pride and Prejudice
# Modifying an elementbookshelf[1] = "The Hobbit"print(bookshelf) # Output: ['Harry Potter', 'The Hobbit', 'Pride and Prejudice', '1984', 'To Kill a Mockingbird']
数组的优点
快速访问:元素可以使用其索引立即访问。
空间效率:数组使用连续的内存块,因此内存效率高。
简单:易于理解和使用。
数组的局限性
实际应用
存储和操作图像像素数据
实现用于科学计算的矩阵
管理用户界面中的项目列表
2. 链表:灵活的链
什么是链表?
链表是一种线性数据结构,其中元素存储在节点中。每个节点包含一个数据字段和对序列中下一个节点的引用(或链接)。与数组不同,链表不会将元素存储在连续的内存位置中。
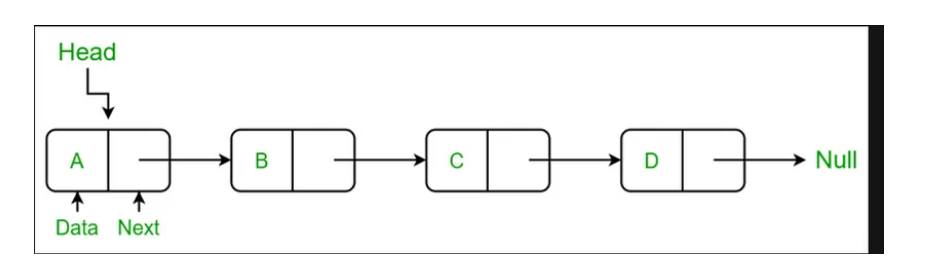
链表如何工作?
链表通过指针连接节点来工作。每个节点都知道序列中的下一个节点,从而形成链式结构。这允许在列表中的任何位置高效地插入和删除元素。
示例:火车类比
将链表想象成一列火车。每节火车车厢(节点)都载有一些货物(数据)并与下一节车厢相连。你可以轻松地在火车的任何位置添加或删除车厢。
class Node: def __init__(self, data): self.data = data self.next = None
class LinkedList: def __init__(self): self.head = None
def append(self, data): new_node = Node(data) if not self.head: self.head = new_node return last_node = self.head while last_node.next: last_node = last_node.next last_node.next = new_node
def display(self): current = self.head while current: print(current.data, end=" -> ") current = current.next print("None")
# Creating a linked listtrain = LinkedList()train.append("Engine")train.append("Passenger Car")train.append("Dining Car")train.append("Cargo Car")
train.display() # Output: Engine -> Passenger Car -> Dining Car -> Cargo Car -> None
链表的优点
链表的局限性
实际应用
在应用程序中实现撤消功能
管理音乐播放列表(可以轻松添加或删除歌曲)
实现哈希表以解决冲突
3. 堆栈:后进先出冠军
什么是堆栈?
堆栈是一种遵循后进先出 (LIFO) 原则的线性数据结构。可以将其视为一叠盘子:您只能从顶部添加或移除盘子。
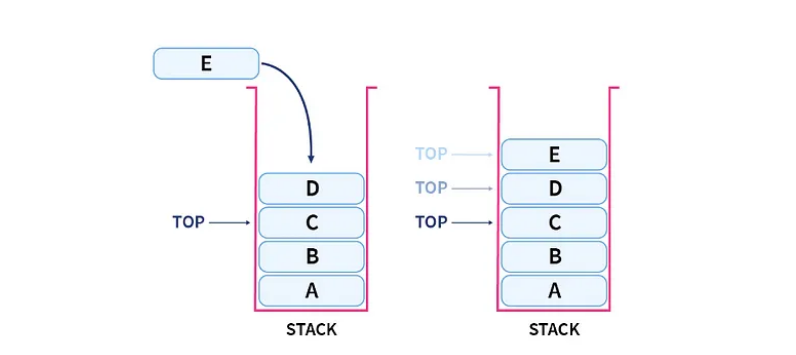
堆栈如何工作?
堆栈通过两个主要操作进行操作:
推送:将元素添加到堆栈顶部。
弹出:从堆栈中删除顶部元素。
示例:浏览器历史记录类比
你的 Web 浏览器的后退按钮功能是堆栈的完美现实示例。当你访问新页面时,它们会被推送到堆栈上。当你点击后退按钮时,你会将页面从堆栈中弹出。
class BrowserHistory: def __init__(self): self.history = []
def visit(self, url): self.history.append(url) print(f"Visited: {url}")
def back(self): if len(self.history) > 1: self.history.pop() print(f"Went back to: {self.history[-1]}") else: print("Can't go back further!")
# Using our browser history stackbrowser = BrowserHistory()browser.visit("google.com")browser.visit("youtube.com")browser.visit("github.com")browser.back()browser.back()browser.back()browser.back()
# Output:# Visited: google.com# Visited: youtube.com# Visited: github.com# Went back to: youtube.com# Went back to: google.com# Can't go back further!
堆栈的优点
简单高效:堆栈操作简单快捷。
内存管理:可用于管理函数调用和递归。
撤消机制:轻松在应用程序中实现撤消功能。
堆栈的局限性
访问受限:任何时候都只能访问顶部元素。
固定大小(在某些实现中):可能有最大大小限制。
实际应用
编程语言中的函数调用管理
表达式求值和语法解析
文本编辑器中的撤消-重做功能
4. 队列:先进先出组织者
什么是队列?
队列是一种遵循先进先出 (FIFO) 原则的线性数据结构。这就像一队人在等公共汽车:排在队伍第一个的人就是第一个上车的人。
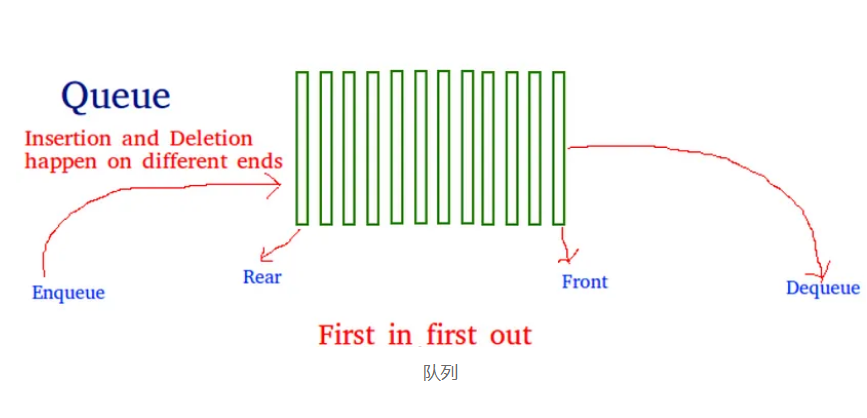
队列如何工作?
队列主要通过两个操作进行操作:
入队:将元素添加到队列后面。
出队:从队列中删除前面的元素。
示例:打印队列类比
打印机队列是队列运行的经典示例。打印作业按接收顺序进行处理。
from collections import deque
class PrinterQueue: def __init__(self): self.queue = deque()
def add_job(self, document): self.queue.append(document) print(f"Added '{document}' to the print queue")
def print_job(self): if self.queue: document = self.queue.popleft() print(f"Printing: {document}") else: print("No jobs in the queue")
def display_queue(self): print("Current queue:", list(self.queue))
# Using our printer queueprinter = PrinterQueue()printer.add_job("Annual Report")printer.add_job("Meeting Minutes")printer.add_job("Employee Handbook")printer.display_queue()printer.print_job()printer.print_job()printer.display_queue()
# Output:# Added 'Annual Report' to the print queue# Added 'Meeting Minutes' to the print queue# Added 'Employee Handbook' to the print queue# Current queue: ['Annual Report', 'Meeting Minutes', 'Employee Handbook']# Printing: Annual Report# Printing: Meeting Minutes# Current queue: ['Employee Handbook']
队列的优点
公平性:确保先到先得的处理。
可预测性:元素按已知顺序处理。
解耦:适用于管理进程之间的异步数据传输。
队列的局限性
实际应用
操作系统中的任务调度
处理 Web 服务器中的请求
图遍历中的广度优先搜索算法
5. 哈希表:闪电般快速的查找大师
什么是哈希表?
哈希表,也称为哈希映射,是存储键值对并提供快速数据检索的数据结构。它们使用哈希函数计算存储桶数组的索引,从中可以找到所需的值。
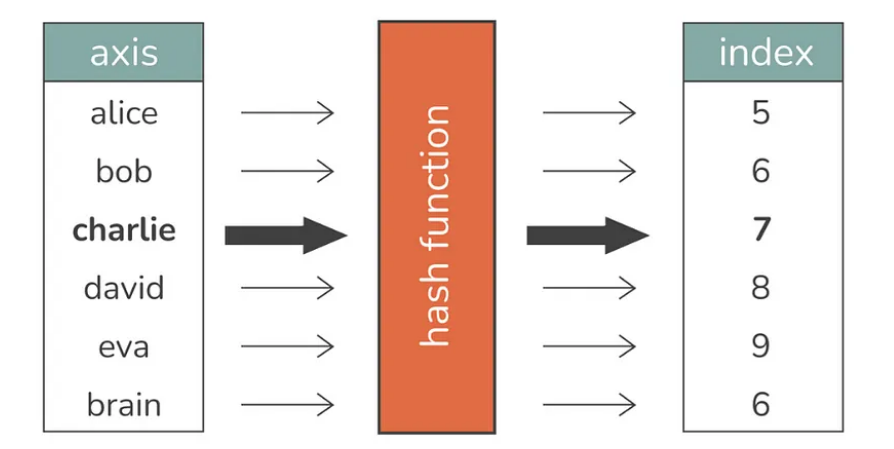
哈希表如何工作?
示例:图书馆目录类比
想象一个图书馆,其中书籍(值)根据从书名派生的唯一代码(键)存储在书架(存储桶)中。此代码由特殊公式(哈希函数)生成。
class SimpleHashTable: def __init__(self, size): self.size = size self.table = [[] for _ in range(self.size)]
def _hash(self, key): return sum(ord(char) for char in key) % self.size
def insert(self, key, value): index = self._hash(key) for item in self.table[index]: if item[0] == key: item[1] = value return self.table[index].append([key, value])
def get(self, key): index = self._hash(key) for item in self.table[index]: if item[0] == key: return item[1] raise KeyError(key)
def display(self): for i, bucket in enumerate(self.table): print(f"Bucket {i}: {bucket}")
# Using our simple hash tablelibrary = SimpleHashTable(10)library.insert("Moby Dick", "Shelf A")library.insert("Pride and Prejudice", "Shelf B")library.insert("The Great Gatsby", "Shelf C")library.insert("To Kill a Mockingbird", "Shelf D")
library.display()print("Location of 'The Great Gatsby':", library.get("The Great Gatsby"))
# Output might look like:# Bucket 0: []# Bucket 1: []# Bucket 2: [['Moby Dick', 'Shelf A']]# Bucket 3: []# Bucket 4: [['Pride and Prejudice', 'Shelf B']]# Bucket 5: [['The Great Gatsby', 'Shelf C']]# Bucket 6: []# Bucket 7: [['To Kill a Mockingbird', 'Shelf D']]# Bucket 8: []# Bucket 9: []# Location of 'The Great Gatsby': Shelf C
哈希表的优点
哈希表的局限性
实际应用
用编程语言实现字典
数据库索引以实现更快的查询
Web 应用程序中的缓存机制
6. 树:分层组织者
什么是树?
树是由通过边连接的节点组成的分层数据结构。它们从根节点开始,然后分支到子节点,形成类似于倒置树的结构。
树如何工作?
树以父子关系组织数据。每个节点可以有多个子节点,但只能有一个父节点(根节点除外)。此结构允许高效搜索和组织分层数据。
示例:家谱类比
家谱是树形数据结构在现实世界中的完美示例。每个人都是一个节点,上面是父母,下面是孩子。
class FamilyMember: def __init__(self, name): self.name = name self.children = []
def add_child(self, child): self.children.append(child)
def display(self, level=0): print(" " * level + self.name) for child in self.children: child.display(level + 1)
# Creating a family treegrandparent = FamilyMember("Grandparent")parent1 = FamilyMember("Parent 1")parent2 = FamilyMember("Parent 2")child1 = FamilyMember("Child 1")child2 = FamilyMember("Child 2")grandchild1 = FamilyMember("Grandchild 1")
grandparent.add_child(parent1)grandparent.add_child(parent2)parent1.add_child(child1)parent1.add_child(child2)child1.add_child(grandchild1)
# Displaying the family treegrandparent.display()
# Output:# Grandparent# Parent 1# Child 1# Grandchild 1# Child 2# Parent 2
树的优点
层次表示:非常适合表示层次关系。
高效搜索:支持快速搜索操作,尤其是在平衡树中。
灵活的结构:可用于实现其他数据结构,如堆和集合。
树的局限性
复杂性:树操作的实现和维护可能很复杂。
内存使用:可能比线性数据结构占用更多内存。
实际应用
7. 图:关系映射器
什么是图?
图是多功能数据结构,表示一组对象(顶点或节点),其中一些对象对通过链接(边)连接。它们是建模复杂关系和网络的理想选择。
图如何工作?
图由顶点(节点)和边(节点之间的连接)组成。边可以是有向的(单向)或无向的(双向)。可以使用邻接矩阵或邻接列表来实现图形。
示例:社交网络类比
社交网络是现实世界中图形的完美示例。每个人都是一个顶点,友谊是连接这些顶点的边。
class SocialNetwork: def __init__(self): self.network = {}
def add_person(self, name): if name not in self.network: self.network[name] = set()
def add_friendship(self, person1, person2): self.add_person(person1) self.add_person(person2) self.network[person1].add(person2) self.network[person2].add(person1)
def display_network(self): for person, friends in self.network.items(): print(f"{person}: {', '.join(friends)}")
# Creating a social networksocial_net = SocialNetwork()social_net.add_friendship("Alice", "Bob")social_net.add_friendship("Alice", "Charlie")social_net.add_friendship("Bob", "David")social_net.add_friendship("Charlie", "David")social_net.add_friendship("Eve", "Alice")
social_net.display_network()
# Output:# Alice: Bob, Charlie, Eve# Bob: Alice, David# Charlie: Alice, David# David: Bob, Charlie# Eve: Alice
图形的优势
关系建模:非常适合表示复杂的关系和连接。
多功能性:可以模拟各种各样的现实场景。
强大的算法:存在许多用于解决复杂问题的图形算法。
图形的局限性
复杂性:对于大型数据集,实现和管理可能很复杂。
内存密集型:存储连接可能需要大量内存。
遍历挑战:某些图形问题的计算成本很高。
现实世界的应用
社交网络分析
GPS 和地图系统
网络路由协议
推荐系统
8. 堆:高效的优先级管理器
什么是堆?
堆是满足堆属性的专用树型数据结构。在最大堆中,对于任何给定节点,节点的值大于或等于其子节点的值。在最小堆中,节点的值小于或等于其子节点的值。
堆如何工作?
堆保持元素的部分排序。它们提供对最大(对于最大堆)或最小(对于最小堆)元素的有效访问,使其成为优先级队列实现的理想选择。
示例:急诊室分诊类比
想象一个急诊室,根据患者病情的严重程度对其进行治疗。该系统可以使用最大堆进行建模,其中优先级最高(病情最严重)的患者始终位于最顶部。
import heapq
class EmergencyRoom: def __init__(self): self.patients = [] self.patient_count = 0
def add_patient(self, name, priority): # We use negative priority for max heap behavior heapq.heappush(self.patients, (-priority, self.patient_count, name)) self.patient_count += 1 print(f"Patient {name} added with priority {priority}")
def treat_next_patient(self): if self.patients: _, _, name = heapq.heappop(self.patients) print(f"Treating patient: {name}") else: print("No patients in waiting.")
def display_queue(self): print("Current queue (Higher number means higher priority):") sorted_patients = sorted(self.patients) for priority, _, name in sorted_patients: print(f" {name}: Priority {-priority}")
# Using our emergency roomer = EmergencyRoom()er.add_patient("John", 3)er.add_patient("Alice", 5)er.add_patient("Bob", 1)er.add_patient("Eve", 4)
er.display_queue()er.treat_next_patient()er.treat_next_patient()er.display_queue()
# Output:# Patient John added with priority 3# Patient Alice added with priority 5# Patient Bob added with priority 1# Patient Eve added with priority 4# Current queue (Higher number means higher priority):# Alice: Priority 5# Eve: Priority 4# John: Priority 3# Bob: Priority 1# Treating patient: Alice# Treating patient: Eve# Current queue (Higher number means higher priority):# John: Priority 3# Bob: Priority 1
堆的优点
堆的局限性
访问受限:只有顶部元素易于访问。
不适合搜索:搜索特定元素可能效率低下。
实现复杂:在操作期间维护堆属性可能很棘手。
实际应用
操作系统中的任务调度程序
数据压缩中的哈夫曼编码
用于在图中查找最短路径的 Dijkstra 算法
编程语言中的内存管理
结论
对于任何希望编写高效且优化的代码的程序员来说,了解这8个基本数据结构都至关重要。每个结构都有自己的优点和缺点,使其适用于不同的场景:
通过掌握这些数据结构,你将能够更好地选择合适的工具来完成工作,从而为各种编程挑战提供更高效、更优雅的解决方案。
请记住,成为一名熟练程序员的关键不仅在于了解这些结构,还在于了解何时以及如何在代码中有效地应用它们。
在继续编程之旅时,练习从头开始实现这些数据结构并在各种场景中使用它们。这种实践经验可以加深你对它们的理解,并帮助你培养在不同情况下使用哪种结构的直觉。
最后,感谢你的阅读,祝编程愉快!
该文章在 2024/10/14 11:11:39 编辑过






 400 186 1886
400 186 1886


